初识块密码
基于比赛的AES搞得我一头雾水所以我转战块密码。
分组加密(Block cipher)
分组加密包含一个成对算法:加密算法E,解密算法D(互为反函数)
每个算法有两个输入:长度为n位的组,和长度为k位的密钥;两组输入均产生n位输出。
将两个算法看作函数,K表示长度为 k的密钥(密钥长度),P表示长度为 n的分组,P也被表示为明文,C表示密文,则满足:
$E_K(P)=C;E^{−1}_K(C)=P$
$ E_K(P):=E(K,P):{0,1}^k×{0,1}^n→{0,1}^n$
每一个密钥实际上是选择了 n位输入排列的 (2n)!种组合中的一种
大多数的分组密码在在加密算法中会重复使用某一函数进行多轮运算,典型的轮数在4-32次之间,每一轮的函数R使用不同的子密钥 Ki,
由原密钥生成,作为输入:
$M_i=R_{Ki}(M_{i−1})$
其中 M0是最初的明文,Mi是第 i轮加密后的密文
AES(Advanced Encryption Standard)
一些问答题目:
1、输入块和输出块之间必须一一对应”的数学术语叫做双射(Bijection),或者称为双射函数。
2、针对AES的最佳但密钥攻击叫做双密码本攻击/双团攻击(Biclique)
3、香农:混淆、扩散
这个函数很有用
1 | def matri2bytes(matrix): |
简而言之,AES-128 首先执行一个“密钥调度”,然后对初始状态进行 10 轮迭代。初始状态就是我们要加密的明文块,以 4x4 字节矩阵的形式表示。在这 10 轮迭代过程中,状态会通过一系列可逆变换反复修改。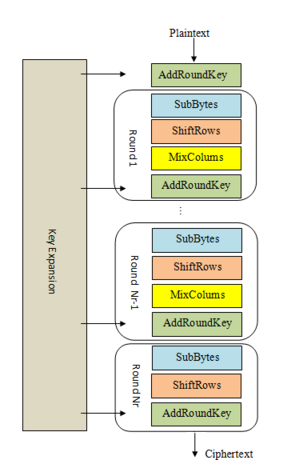
1.密钥扩展或密钥调度:
从128位密钥派生出11个独立的128位“轮密钥”:每个AddRoundKey步骤使用一个轮密钥。轮密钥生成
接收我们提供的 16 字节密钥,并生成 11 个 4x4 矩阵,称为“轮密钥”
2.初始密钥添加
AddRoundKey:将第一个轮密钥的字节与状态的字节进行异或运算。
3.轮加密:此阶段循环10次,共9个主轮和1个“最终轮”
(a) SubBytes:根据查找表(“S盒”)将状态的每个字节替换为不同的字节。
AES 每轮加密的第一步是SubBytes 操作。这一步涉及将状态矩阵中的每个字节替换到一个预设的 16x16 查找表中对应的字节。这个查找表被称为“替换盒”(Substitution box),简称“S”盒S盒
多项式的次数越高,求解难度通常就越大——它只能用越来越多的线性函数来近似。S盒的主要目的是以一种难以用线性函数近似的方式变换输入。S盒的目标是实现高度非线性,虽然AES的S盒并不完美,但已经非常接近了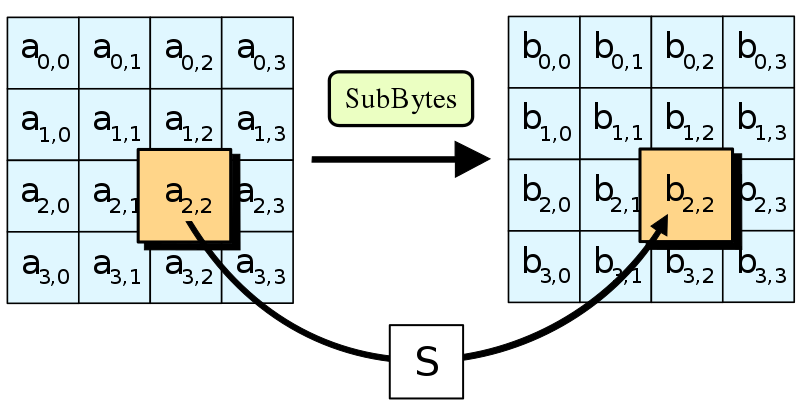
原理:S盒中的快速查找是执行对输入字节进行高度非线性函数运算的快捷方式。该函数涉及在伽罗瓦域2**8中取模逆,然后应用一个经过调整以最大程度混淆的仿射变换。
1 | s_box = ( |
替换本身会产生非线性,但它并不能将非线性分布到整个状态。如果没有扩散,同一位置的同一字节在每一轮都会被应用相同的变换。这将允许密码分析者分别攻击状态矩阵中的每个字节位置。我们需要通过(以可逆的方式)扰乱状态来交替进行替换,使得应用于一个字节的替换会影响状态中的所有其他字节。这样,下一个S盒的每个输入就变成了多个字节的函数,这意味着随着每一轮的进行,系统的代数复杂度都会急剧增加。理想的扩散量会导致明文中一位的变化,在统计意义上导致密文中一半的比特发生变化。这种理想的结果被称为雪崩效应。
(b) ShiftRows:将状态矩阵的最后三行转置——向左移动一列、两列或三列。
ShiftRows是 AES 中最简单的变换。它保持状态矩阵的第一行不变。第二行向左移动一列,循环往复。第三行向左移动两列,第四行向左移动三列。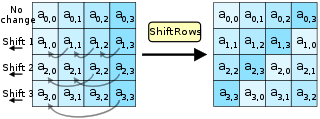
1 | def shift_rows(s): |
这是 AES 的 ShiftRows 操作。代码用列旋转的方式等价实现了行的循环左移。
根据左移位数对应右移相应位数
1 | def inv_shift_rows(s): |
(c) MixColumns:对状态的列执行矩阵乘法,将每列中的四个字节组合在一起。最终轮跳过此步骤。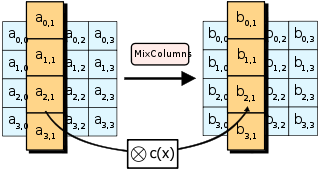
在 Rijndael Galois 域中对状态矩阵的列和预设矩阵进行矩阵乘法运算。因此,每一列的每个字节都会影响结果列的所有字节
1 | def mix_single_column(a): |
逆列混淆
1 | def inv_mix_columns(s): |
(d) AddRoundKey:将当前轮密钥的字节与状态的字节进行异或运算。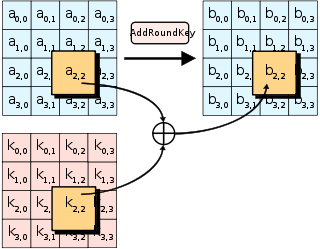
例题
1 | state = [ |
exp
1 | state = [ |
1 | from Crypto.Cipher import AES |
DES
数据加密标准(英语:Data Encryption Standard,缩写为 DES)是一种对称密钥加密块密码算法,1976年被美国联邦政府的国家标准局确定为联邦资料处理标准(FIPS),随后在国际上广泛流传开来。它基于使用56位密钥的对称算法。这个算法因为包含一些机密设计元素,相对短的密钥长度以及怀疑内含美国国家安全局(NSA)的后门而在开始时有争议,DES因此受到了强烈的学院派式的审查,并以此推动了现代的块密码及其密码分析的发展。
DES现在已经不是一种安全的加密方法,主要因为它使用的56位密钥过短。
DES是一种典型的块密码—一种将固定长度的明文通过一系列复杂的操作变成同样长度的密文的算法。对DES而言,块长度为64位。同时,DES使用密钥来自定义变换过程,因此算法认为只有持有加密所用的密钥的用户才能解密密文。密钥表面上是64位的,然而只有其中的56位被实际用于算法,其余8位可以被用于奇偶校验,并在算法中被丢弃。因此,DES的有效密钥长度仅为56位。
算法的整体结有16个相同的处理过程,称为“回次”(round),并在首尾各有一次置换,称为IP与FP(或称IP-1,FP为IP的反函数(即IP“撤销”FP的操作,反之亦然)。IP和FP几乎没有密码学上的重要性,为了在1970年代中期的硬件上简化输入输出数据库的过程而被显式的包括在标准中。
在主处理回次前,数据块被分成两个32位的半块,并被分别处理;这种交叉的方式被称为费斯妥结构。费斯妥结构保证了加密和解密过程足够相似—唯一的区别在于子密钥在解密时是以反向的顺序应用的,而剩余部分均相同。这样的设计大大简化了算法的实现,尤其是硬件实现,因为没有区分加密和解密算法的需要。
费斯妥函数(F函数)将数据半块与某个子密钥进行处理。然后,一个F函数的输出与另一个半块异或之后,再与原本的半块组合并交换顺序,进入下一个回次的处理。在最后一个回次完成时,两个半块需要交换顺序,这是费斯妥结构的一个特点,以保证加解密的过程相似。
费斯妥函数(F函数)每次对半块(32位)进行操作,并包括四个步骤:
扩张 用扩张置换将32位的半块扩展到48位,其输出包括8个6位的块,每块包含4位对应的输入位,加上两个邻接的块中紧邻的位。
与密钥混合 用异或操作将扩张的结果和一个子密钥进行混合。16个48位的子密钥—每个用于一个回次的F变换—是利用密钥调度从主密钥生成的。
S盒 在与子密钥混合之后,块被分成8个6位的块,然后使用“S盒”,或称“置换盒”进行处理。8个S盒的每一个都使用以查找表方式提供的非线性的变换将它的6个输入位变成4个输出位。S盒提供了DES的核心安全性—如果没有S盒,密码会是线性的,很容易破解。
置换 最后,S盒的32个输出位利用固定的置换,“P置换”进行重组。这个设计是为了将每个S盒的4位输出在下一回次的扩张后,使用4个不同的S盒进行处理。
S盒,P置换和E扩张各自满足了克劳德·香农在1940年代提出的实用密码所需的必要条件,“混淆与扩散”。
在DES的计算中,56bit的密钥最终会被处理为16个轮密钥,每一个轮密钥用于16轮计算中的一轮,DES弱密钥会使这16个轮密钥完全一致,所以称为弱密钥。
四个弱密钥
1 | \x01\x01\x01\x01\x01\x01\x01\x01 |
1 | \x00\x00\x00\x00\x00\x00\x00\x00 |
如果使用弱密钥,PC1计算的结果会导致轮密钥全部为0、全部为1或全部01交替。
因为所有的轮密钥都是一样的,并且DES是 Feistel网络的结构,这就导致加密函数是自反相 (self-inverting) 的,结果就是加密一次看起来没什么问题,但是如果再加密一次就得到了明文。
部分弱密钥
部分弱密钥是指只会在计算过程中产生两个不同的子密钥,每一个在加密的过程中使用8次。这就意味着这对密钥k1
和 k2
有如下性质:Ek1(Ek2(M))=M
。
6个常见的部分弱密钥对:
1 | 0x011F011F010E010E + 0x1F011F010E010E01 |
模式攻击
ECB模式
电子密码本模式
ecb模式使用相同的key分块对明文分别进行加密,相同的明文获得相同的密文输出
将需要加密的块按照块密码的大小被分为数个块,并对每个块进行独立加密。
中间人攻击(MITM)
假如存在一个攻击者,当他作为中间人截获双方通信时,他能够改变密文的分组顺序,当接收者对密文进行解密时,由于密文分组的顺序被改变了,因此相应的明文分组的顺序也被改变了,那么接收者实际上是解密出了一段被篡改后的密文。在这种场景中,攻击者不需要破译密码,也不需要知道分组密码的算法,他只需要知道哪个分组记录了什么样的数据。
1 | #python2 |
本质:
正向计算:从明文出发,用所有可能的 key1 加密,将结果存入字典 middle。
反向计算:从密文出发,用所有可能的 key2 解密,看结果是否在字典 middle 中。
相遇:如果“正向加密的结果”等于“反向解密的结果”,那么我们就找到了正确的密钥对。
模式攻击
动态填充加密+枚举secret字符
法一
明文由输入值m+flag+padding组成,m为空时,c可分k块,调整m的长度直到m的长度为l+1时,c可分为k+1块,说明当m长度为l时c刚好可以分为k块此时没有多余padding。
m+flag可分为k块,则flag的长度即为8k-l
利用上面的思想,在 m长度为 l的基础上,长度不断加1,则可以把flag从后开始的每一位推到下一个块中,得到下一个块的密文 ci
根据已经爆破的flag位+padding->下一个块的构成位、为未知字符1位+已爆破出的flag位+padding
DES-ECB->
相同明文块对应密文块相同。将上面的块作为输入->得到下一个块的密文再与密文ci比较。
CBC模式
密文分组链接模式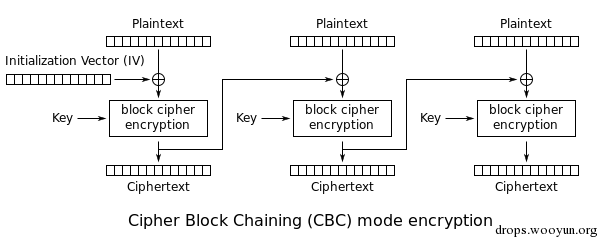
CTR模式
全称CounTeR计数器模式
1 | CTR模式中,每个分组对应一个逐次累加的计数器,并通过对计数器进行加密来生成密钥流。也就是说,最终的密文分组是通过将计数器加密得到的比特序列,与明文分组进行XOR而得到的。 |
加密:
解密
1 | 每次加密时都会生成一个不同的值(nonce)来作为计数器的初始值。当分组长度为128比特(16字节)时,计数器的初始值可能是像下面这样的形式。 |
1 | 其中前8个字节为nonce(随机数),这个值在每次加密时必须都是不同的,后8个字节为分组序号,这个部分是会逐次累加的。在加密的过程中,计数器的值会产生如下变化: |

按照上述生成方法,可以保证计数器的值每次都不同。由于计数器的值每次都不同,因此每个分组中将计数器进行加密所得到的密钥流也是不同的。也是说,这种方法就是用分组密码来模拟生成随机的比特序列。
1 | CTR模式和OFB模式一样,都属于流密码。如果我们将单个分组的加密过程拿出来,那么OFB模式和CTR模式之间的差异还是很容易理解的(下图)。OFB模式是将加密的输出反愦到输入,而CTR模式则是将计数器的值用作输入。 |
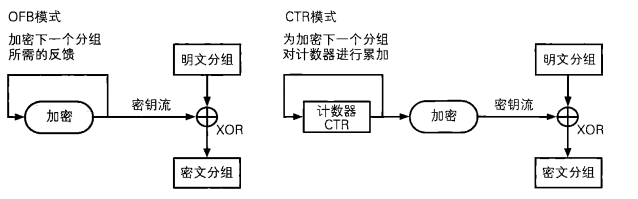
特点:
解密和加密结构完全相同,流密码OFB模式也有此特点
CTR模式中可以以任意顺序对分组进行加密和解密,因此在加密和解密时需要用到的“计数器”的值可以由nonce和分组序号直接计算出来。这一性质是OFB模式所不具备的
能够以任意顺序处理分组,就意味着能够实现并行计算。在支持并行计算的系统中,CTR模式的速度是非常快的
CFB模式
密文反馈模式
OFB模式
输出反馈模式




